Exploring Text Embeddings for Financial Documents
Jonathan Wang, Daniela De la Parra, Clifford Thompson, Kena Du
Final Project for ELEC/COMP 576: Introduction to Deep Learning, Rice University
December 2018
Introduction
10-Ks are annual reports required by the Security and Exchange Commission, which give a comprehensive picture of the financial and managerial position of publicly-traded companies. Many investors primarily focus on financial statements and other numeric data from these reports. Our analysis focuses instead on textual data from Item 1 - Business, and Item 7 - Management’s Discussion and Analysis. We believe textual data in these sections can be analyzed to glean meaning about the operations and financial position of companies.
Our project uses three architectures to solve this problem, Word2Vec [1, 2], Doc2Vec [3], and Skip-Thoughts [4]. Our goal is to explore text embeddings for these 10-Ks, and determine what information about a company is correlated with the text. A secondary goal is to test the strengths and weaknesses of each method, as well as use-cases and important parameters of variation.
With each architecture, we created two text embeddings and did an exploration on the performance/meaning of these embeddings. We tested both 2-dimensional and 100-dimensional embeddings, to establish the bounds of a reasonable range for replication. As we will elaborate below, these two different dimension choices produced a tradeoff between the cluster hierarchy and the accuracy of the word predictions.
Our results give specific avenues for improvement in the future. We were able to conclude from our exploration that using deep learning architectures to determine text embeddings is definitely feasible for these documents, but the methods require significant data and analysis to understand the meaning of the embeddings. One major lesson we learned is the difficulty of combining word and document level embeddings due to embedding size. Doc2Vec has an advantage over Word2Vec and Skip-Thoughts in that the document embedding dimension is independent from the component embedding dimensions.
Data
Our raw data is derived from approximately 93,000 10-K filings from 1993 to 2017 that we downloaded from the SEC’s EDGAR website. We chose to extract two key sections from approximately 28,000 of these filings. The sections we examined are:
- Item 1. – Business
- Item 7. – Management’s Discussion and Analysis
We extracted all the textual information from these documents, removing noisy characters and breaking up documents into sentences, and then encoding the words into integer tokens. The resulting dataset was composed of 27,588 filings, with an average of 313 sentences and 8,934 words. Our vocabulary was limited to the most frequent 10,000 words, and all numbers were replaced with a [number] token.
Method Overview
We explored three different models for text embedding to extract information from the 10-K document text - Word2Vec (skip-gram), Doc2Vec (PV-DM), and Skip-Thought Vectors.
Word2Vec
Word2Vec (skip-gram) [1, 2] embeds words by trying to predict the neighboring words given an input word. It learns the context in which words are used, to eventually grasp the meaning of a word stored in the embedding. The architecture and learning task is summarized in Figure 1. Once the words in a document are embedded, we average them to produce an embedding for the entire document [5]. One limitation of this approach is that the document embeddings must be the same length as the word embeddings.
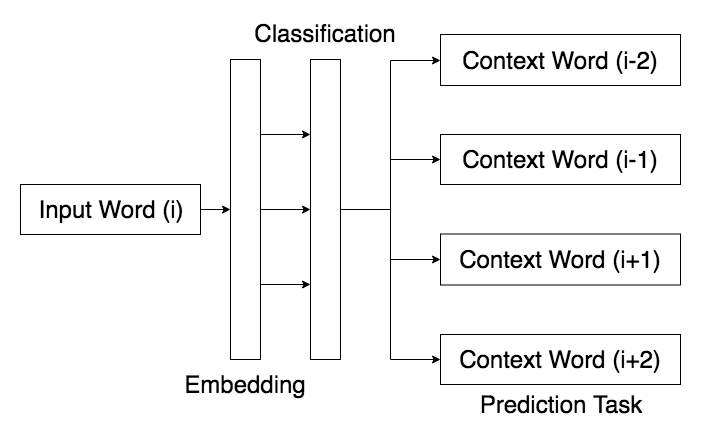
Figure 1. Word2Vec Model Outline
Doc2Vec
Doc2Vec (PV-DM) [3] embeds words and documents simultaneously. The model takes in the document id and neighboring words to predict the target word, similar to Word2Vec. However, Doc2Vec produces a vector for the entire document, rather than a vector simply at the sentence level. This is outlined in Figure 2. This model produces a document embedding independent of the word embeddings.
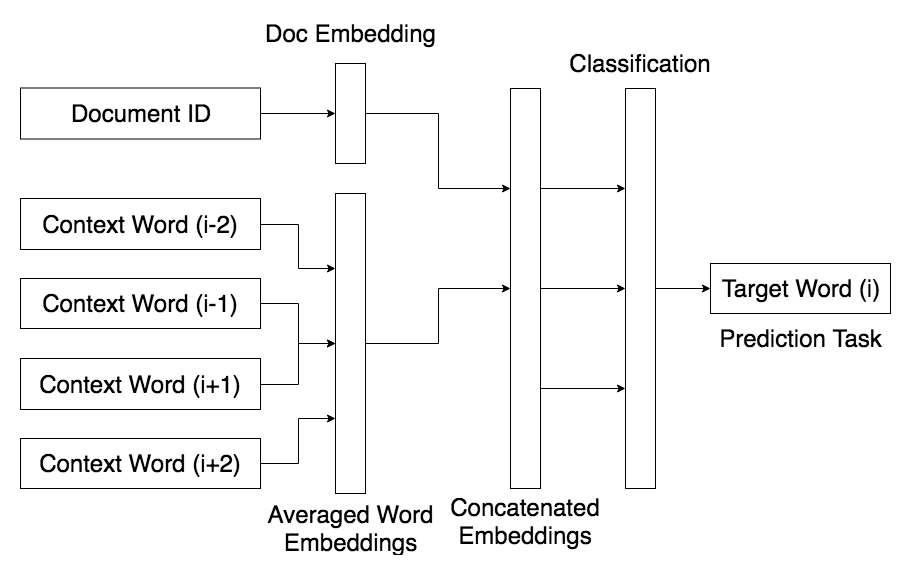
Figure 2. Doc2Vec Model Outline
Skip-Thought Vectors
Skip-Thought Vectors [4] are similar to the Word2Vec skip-gram model, except they operate at the sentence level instead of the word level. The model is an encoder-decoder architecture that takes in a sentence and predicts neighboring sentences using the decoder. The internal cell state of the encoder will learn a sentence embedding from the input words. This architecture is shown in Figure 3. We extracted sentence embeddings from the encoder and averaged them over the document to produce a document embedding [5].
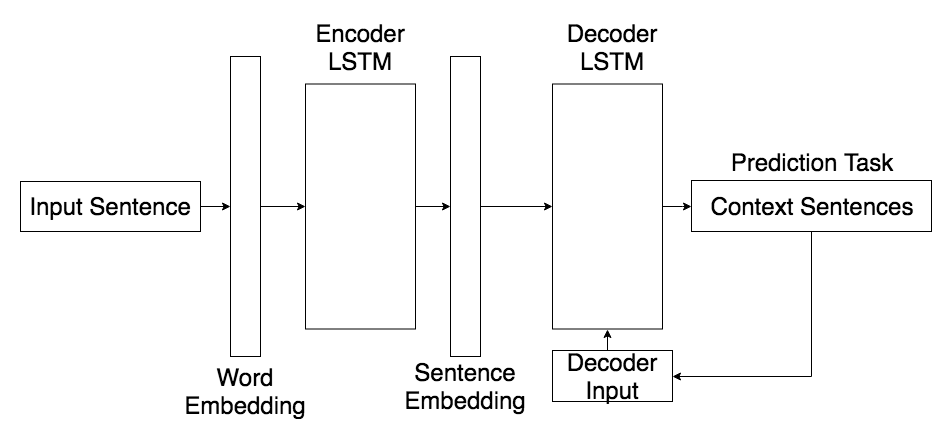
Figure 3. Skip-Thought Model Outline
Results
For all three methods, Word2Vec, Doc2Vec (PV-DM), and Skip-Thoughts, we generated both 2-dimensional and 100-dimensional embeddings. Our intention was to examine the different meanings captured by the embeddings, as well as how to use them to cluster the source 10-K documents.
Word2Vec
For Word2Vec, the 100-dimensional embedding produced expected results given the template form common in the MD&A and Business sections of 10-Ks. Our model clustered companies’ annual filings together by company. As we can see from the dendrogram in Figure 4, the clusters themselves are quite tight and far apart at a 100-dimensional embedding.
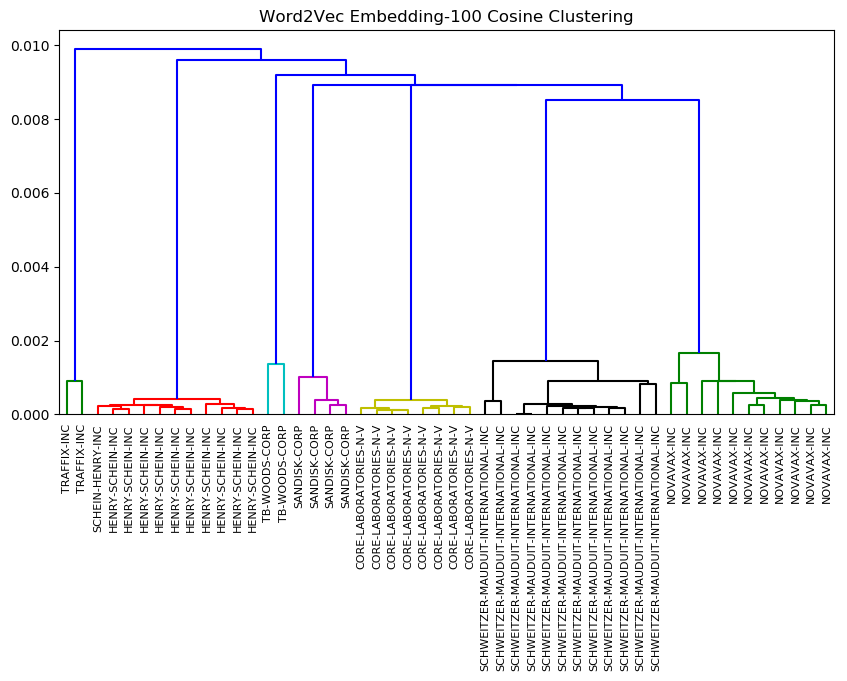
Figure 4. Clusters from Word2Vec 100-Dimension Embedding
In contrast, the clusters produced by our 2-dimensional embedding had a more regular hierarchy (Figure 5).
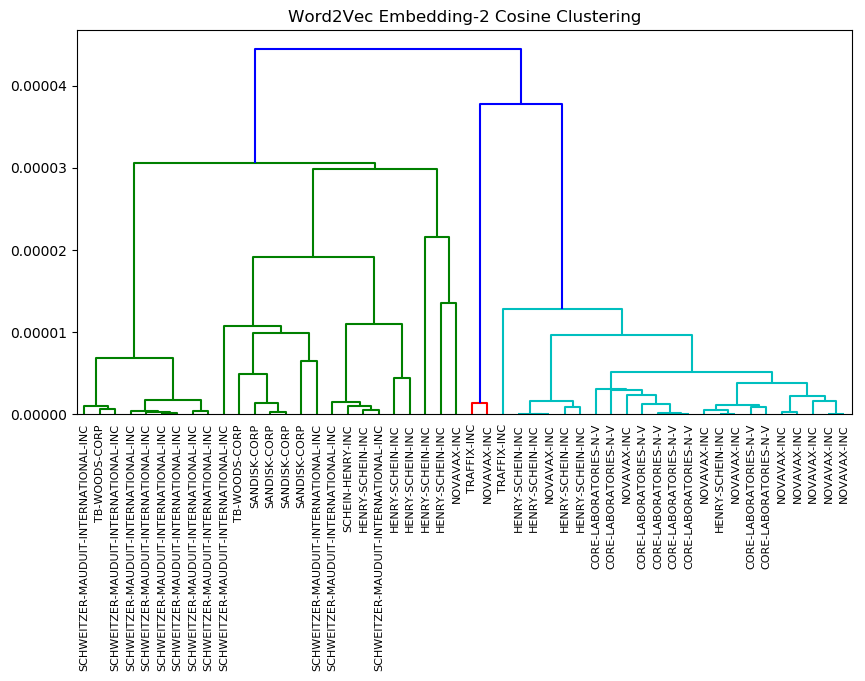
Figure 5. Clusters from Word2Vec 2-Dimension Embedding
This makes intuitive sense; with fewer dimensions to categorize the word-level text embedding, each company is more similar to others given that there are fewer dimensions to categorize word differences. It is possible that combining all of the word-level embeddings resulted in capturing document syntax rather than meaning, which would explain the company-wise clusters. However, there may be other features that were captured that are company-related information.
The Word2Vec 100-dimensional embedding also produced good outputs for predicted words, for example from Item 1 - Business:
Nearest to “regulations”: rules, requirements, laws, regulation, policies, promulgated, standards
In contrast, Word2Vec’s 2-dimensional embedding produced poor predicted word outputs. Again from Item 1 - Business:
Nearest to “international”: holes, anemia, [number]g, border, vein, amount, chronic, mouth
In the above example, “[number]” is a token we used in place of numeric data, to avoid the confounding effect of numbers. However, like “mouth” and “anemia,” it is not a reasonable predicted synonym for “international.”
Doc2Vec
For Doc2Vec (PVDM), both 2-dimensional and 100-dimensional embeddings produced more complex results, as shown in Figures 6 and 7. Unlike Word2Vec, the dendrograms are capturing meaning that is not related simply to standard language templates, so the clusters are not single-company clusters. We can see that both dendrograms cluster companies by some parameter that does not group the same company’s financials across multiple years. This is an area for further study, since it is not obvious from our limited label data what feature the clusters are being formed on.
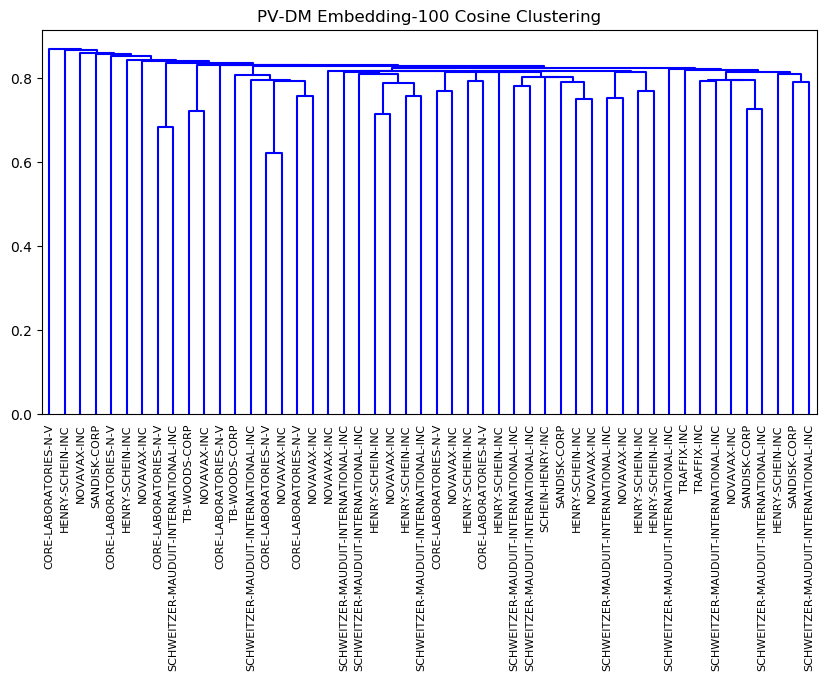
Figure 6. Clusters from Doc2Vec 100-Dimension Embedding
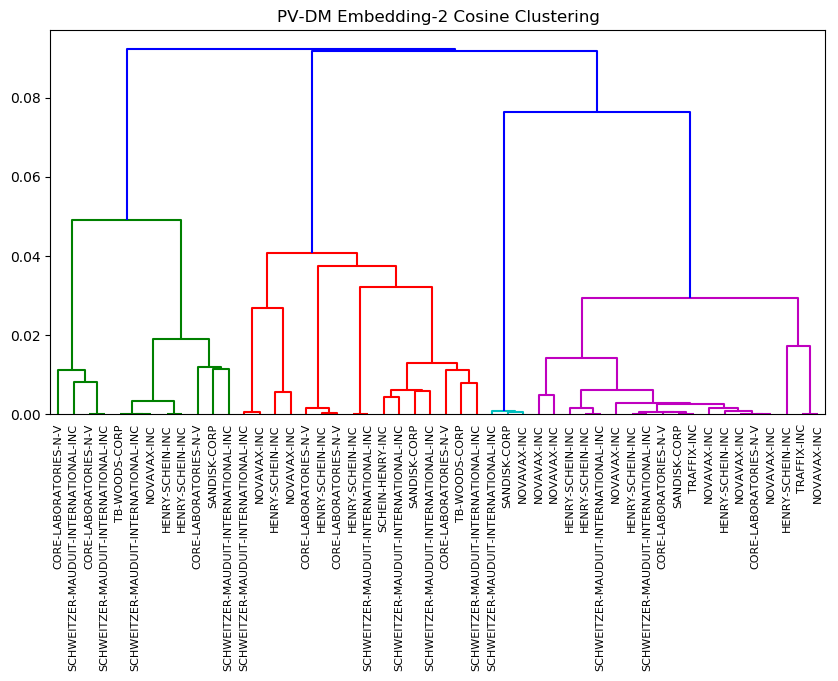
Figure 7. Clusters from Doc2Vec 2-Dimension Embedding
Compared to the 2-dimensional embedding, the Doc2Vec 100-dimension embedding produced very poor clusters. The information captured by the embedding is probably insignificant compared to the dimension of the embedding. Thus, each individual document embedding is very far from all other embeddings. As a result, we conclude that a lower dimension embedding is preferable for Doc2Vec.
Since the 2-dimensional embedding defines clear clusters, we can assume that the higher dimensional embedding also contains information about category distinctions. However, at this time we do not have the means to parse category distinctions for the 100-dimensional embedding.
For Doc2Vec, both 100-dimensional and 2-dimensional word predictions were strong. It is important to clarify that our model still uses a 100-dimensional word embedding, even when using a 2-dimensional document embedding. This is an important point for future replication: when changing the document embedding dimension, the Doc2Vec architecture also has a separate word embedding dimension. This is one key advantage of the Doc2Vec embedding compared to the other embedding methods. Unsurprisingly, the example below is comparable for both 2-dimensional and 100-dimensional document embeddings.
- 100-dimensional document embedding:
Nearest to “manufacturing”: production, distribution, development, processing, drilling, gourmet, powered, sdwa
- 2-dimensional document embedding:
Nearest to “credit”: loan, financing, subordinated, therein, debt, abl, shire, solicitation
In the above word predictions, “sdwa” refers to the Safe Drinking Water Act, a regulatory consideration for manufacturers. “abl” refers to asset-based lending, a business loan secured with an asset or assets as collateral.
One interesting artifact is the identification of commodities at the document embedding level. We can see that the 100-dimensional document embedding with a 100-dimensional word embedding captured both “grain” and “corn” as similar to “oil”:
Nearest to “oil”: natural, exploration, water, grain, corn, davis, interstate, outerwear
Both “natural” and “exploration” make reasonable sense. Davis Petroleum is a company in our dataset, and “interstate” has a natural connection to transportation and infrastructure. However, the team could not find a simple interpretation of “outerwear.”
Skip-Thought Vectors
The dendrograms produced by the model using a 100-dimensional embedding in the Skip-Thought architecture were clustered in a regular hierarchy similar to the two-dimensional clusters of the other models. In the Item 1: Business cluster, two filings from one company, TB-Woods Corp., were identified as significantly different from the rest of the filings. (Figure 8)
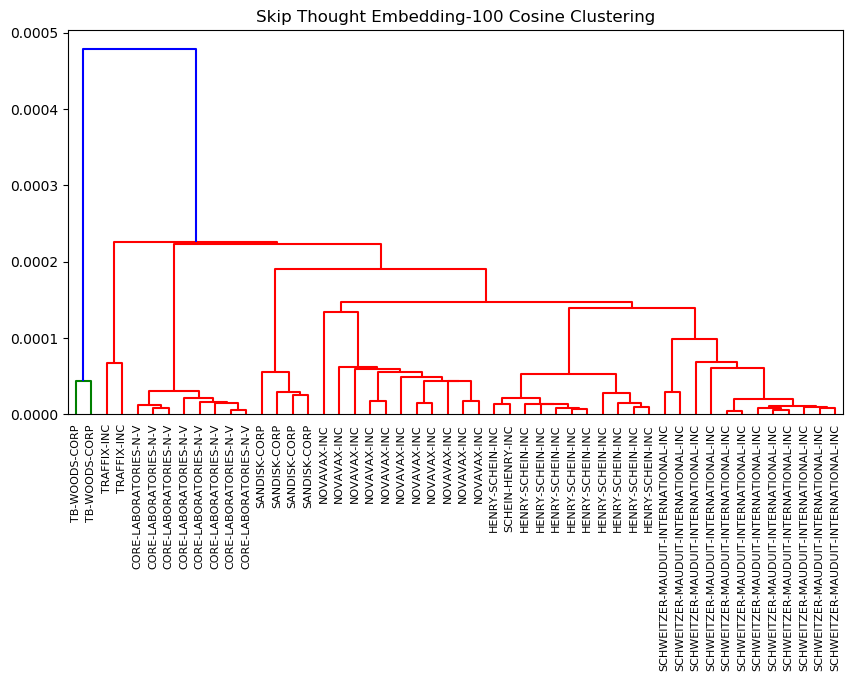
Figure 8. Clusters from Skip-Thoughts 100-Dimension Embedding (Business Section)
When we ran our model using Skip-Thoughts with 2-dimensional embeddings, the predicted sentences were repeated and unclear. Compared to the Word2Vec and Doc2Vec architectures, these predicted sentences were bad enough that we determined that 2-dimensional embeddings are unsuitable for use with the Skip-Thoughts architecture. There was not enough meaning preserved in the word embeddings to produce a reasonable thought vector. See below for an example.
Input sentence: our actual results may differ materially from the results discussed in these forward looking statements
Decoded sentence: and of the the the the the the the the the the the the the the the the the the the
From a statistical perspective, one potential explanation is that at the document-wide level, it is much more likely for any given word to be a preposition or common article when the embedding space has low dimensional resolution and cannot distinguish context well.
In contrast, the 100-dimensional embedding was surprisingly effective at constructing sentences which captured the essence of the “thought vector” behind a given input sentence.
Input sentence: our actual results may differ materially from the results discussed in these forward looking statements
Decoded sentence: are joined variety of operations and are subject to change
Because of the unsuitability of a 2-dimensional embedding with the Skip-Thoughts architecture, we include a dendrogram from the MD&A sections of these 10-Ks to compare with the above dendrogram of the Business sections. Again, this dendrogram uses a 100-dimension embedding (Figure 9)
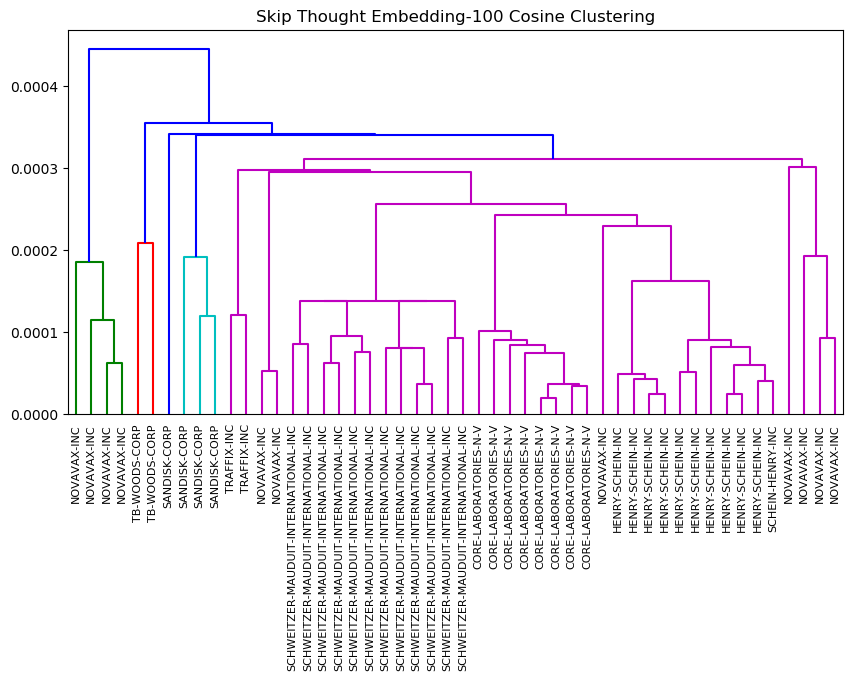
Figure 9. Clusters from Skip-Thoughts 100-Dimension Embedding (MD&A Section)
We can see that at the most basic clustering level, companies’ 10-Ks across multiple years are clustered together. This makes intuitive sense. More research will be helpful to determine more specific aspects of this hierarchy, and the correlation with factors like industry and earnings.
Analysis
Doc2Vec was our sole method with a pure document embedding, not a sum of sub-embeddings. We could not interpret the clusters generated by this higher-level embedding. However, other embeddings like word or sentence embeddings were clearly clustered according to companies. We interpret this as our model finding syntactical meaning or company-oriented features. Parsing the meaning of the Doc2Vec 100-dimensional embedding clusters is the primary area for continued study and replication following this project.
To judge the success of Doc2Vec, the word-level embedding is less important than the document-level embedding. While necessary to properly apply Doc2Vec, predicting the target word is a less important task from the perspective of gleaning document-level meaning. Furthermore, we expect that a document-level embedding requires less resolution to accurately capture document-level meaning. There are fewer document-level meanings within our dataset than word-level meanings.
Compared to Word2Vec or Skip-Thoughts embeddings, the Doc2Vec embedding is independent of the component embeddings, both in terms of dimension as well as meaning. This is one potential explanation for the unintuitive hierarchical clusters generated by Doc2Vec with a 2-dimensional embedding. However, this also makes it a strong candidate for future exploration for this task, since it can capture more interesting meanings through embeddings.
Conclusion
The results of our project are as follows:
- Determined the applicability of text embedding models to financial statements
- Determined how changing parameters affects the output from our models
- Determined important factors for efficiently running similar models
The goal of our project was to understand how text embedding models work and try applying them to financial documents. For this reason, and the fact that our data was fairly specific, we decided to build models from scratch. Given our limited time frame, we successfully trained embeddings to represent words, as well as documents. Our output accurately classified 10-K filings by company across multiple years, and it had reasonable success with predicting output words and identifying some cross-industry business similarities like commodities. With more computational power and a fuller and cleaner dataset, these text embedding models could easily be applied to obtain more specific information from the 10-K documents.
References
- T. Mikolov, et al. “Efficient Estimation of Word Representations in Vector Space.” Arxiv. 2013.
- T. Mikolov, et al. “Distributed Representations of Words and Phrases and their Compositionality.” NIPS. 2013.
- Q. Le and T. Mikolov. “Distributed Representations of Sentences and Documents.” ICML. 2014.
- R. Kiros, et al. “Skip-Thought Vectors.” NIPS. 2015.
- S. Arora, Y. Liang, and T, Ma. “A Simple but Tough-to-Beat Baseline for Sentence Embeddings.” ICLR. 2017.
- F. Chollet “Deep Learning with Python.” Manning. 2018.